
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- i2c 통신
- uart 통신
- hc-sr04
- ATMEGA128A
- Recursion
- half adder
- test bench
- FND
- soc 설계
- java
- gpio
- D Flip Flop
- Edge Detector
- BASYS3
- vivado
- stop watch
- verilog
- KEYPAD
- ring counter
- pwm
- Linked List
- Algorithm
- atmega 128a
- structural modeling
- prescaling
- dataflow modeling
- LED
- DHT11
- behavioral modeling
- Pspice
- Today
- Total
거북이처럼 천천히
Verilog RTL 설계 (6월 13일 - 3) 본문
1. 4bit 병렬 가감산기
- 4비트 병렬 가감산기의 논리 회로도 (블록도)는 다음과 같다.
- 이전 게시글에서 다루었던 4bit 병렬 가산기 경우에는 가산기로서 역활밖에 수행 할 수 없었지만, 병렬 가감산기는 뺄셈 연산을 2의 보수를 취해줌으로서 뺄셈연산도 수행 할 수 있다.
- 4비트 병렬 가감산기의 논리 회로도 (블록도)는 다음과 같다.

- Q) 어떻게 2의 보수가 적용되는가?
- A) B가 0보다 작은 음수인 경우, 가산기를 통해 연산하기 위해 2의 보수를 해줄 필요가 있다.
이를 위해 Sign 값과 XOR 게이트를 활용하는데, XOR 게이트를 통해 1의 보수를 수행할 수 있으며,
Sign 도선을 통해 1을 더해줌으로서 최종적으로 2의 보수를 수행 할 수 있다. - 주의)
Q) 4bit 병렬 가감산기의 출력 값의 범위는 어디에서부터 어디까지 인가? - A) 4bit 병렬 가감산기의 출력 값은 양수, 0, 음수 범위를 모두 표현하기 때문에 4bit 가감산기의 출력
값은 -8 ~ 7까지 갖기 때문에 이점을 유념할 필요가 있다. 만약, 연산 결과가 이를 넘어가면 의도와
다르게 overflow, underflow 가 발생하여 잘못 출력될 수 있기 때문에 이점을 유념하자.
2. 4bit - parallel add / subtractor ( Structural Modeling by using library gate)
< Source >
// Half-adder (Structural Modeling)
module half_adder (
input a, b,
output sum, carry );
and(carry, a, b);
xor(sum, a, b);
endmodule
// Full-adder (Structural Modeling)
module full_adder (
input a, b, Cin,
output sum, carry );
wire sum_0, carry_0, carry_1;
half_adder half_adder0(a, b, sum_0, carry_0);
half_adder half_adder1(sum_0, Cin, sum, carry_1);
xor(carry, carry_0, carry_1);
endmodule
// 4bit parallel add / subtraction (Structural Modeling)
module Parallel_add_subs_4bit_Dataflow_Modeling(
input [3:0] a, b,
input Cin,
output [3:0] sum,
output carry );
// complement wire
wire[3:0] complement_b;
// carry wire of each full adder
wire[2:0] carry_full_adder;
// b's 2's complement
xor(complement_b[0], Cin, b[0]);
xor(complement_b[1], Cin, b[1]);
xor(complement_b[2], Cin, b[2]);
xor(complement_b[3], Cin, b[3]);
// Each full adder
full_adder full_adder0 (a[0], complement_b[0], Cin, sum[0], carry_full_adder[0]);
full_adder full_adder1 (a[1], complement_b[1], carry_full_adder[0], sum[1], carry_full_adder[1]);
full_adder full_adder2 (a[2], complement_b[2], carry_full_adder[1], sum[2], carry_full_adder[2]);
full_adder full_adder3 (a[3], complement_b[3], carry_full_adder[2], sum[3], carry);
endmodule
< Simulation >
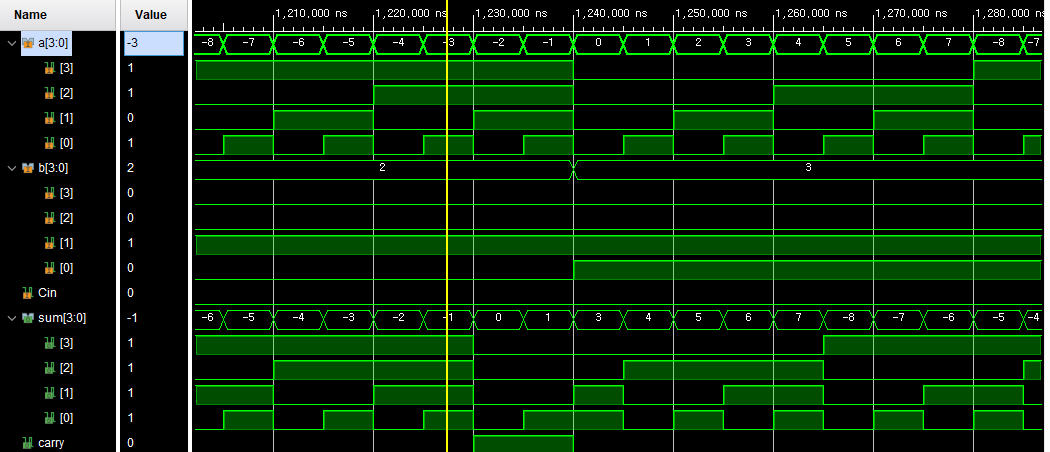
- 주의) 4bit 병렬 가감산기의 출력값은 -8 ~ 7 까지 표현이 가능함을 기억하자.
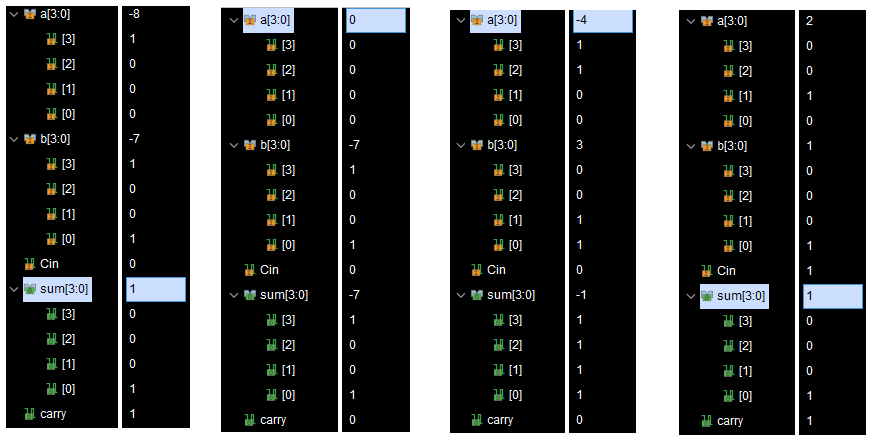
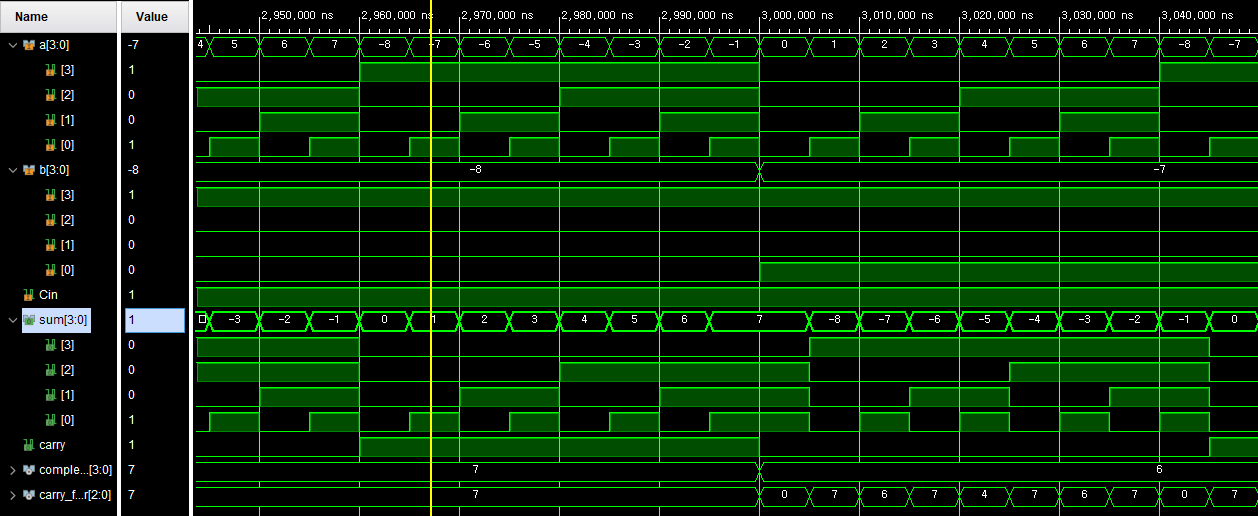
- ex) a = 7, b = -4일 경우, a + b = 3이기 때문에 출력 값이 정상적으로 출력했음을 확인.
a = -7, b = -4일 경우, a + b = -11이지만, underflow가 발생하여 의도와 다른 5가 출력했음을 확인.
a = 7, b =3일 경우, a + b = 10이지만, overflow가 발생하여 의도와 다른 -6가 출력했음을 확인.

3. 4bit - parallel add / subtractor ( Structural Modeling by using module gate)
< Source >
// and gate (behavioral modeling)
module and_gate (
input a, b,
output reg out);
always @(a, b) begin
case({a, b})
2'b00 : out = 0;
2'b01 : out = 0;
2'b10 : out = 0;
2'b11 : out = 1;
endcase
end
endmodule
// xor gate (behavioral modeling)
module xor_gate (
input a, b,
output reg out );
always @(a, b) begin
case({a, b})
2'b00 : out = 0;
2'b01 : out = 1;
2'b10 : out = 1;
2'b11 : out = 0;
endcase
end
endmodule
// half adder (structural modeling)
module half_adder (
input a, b,
output sum, carry );
and_gate and0 (.a(a), .b(b), .out(carry));
xor_gate xor0 (.a(a), .b(b), .out(sum));
endmodule
// full adder (structural modeling)
module full_adder (
input a, b, Cin,
output sum, carry );
wire sum_0, carry_0, carry_1;
half_adder half0(.a(a), .b(b), .sum(sum_0), . carry(carry_0));
half_adder half1(.a(Cin), . b(sum_0), .sum(sum), .carry(carry_1));
xor_gate xor0(.a(carry_0), . b(carry_1), .out(carry));
endmodule
// 4bit paralledl adder / subtractor (structural modeling)
module Parallel_add_subs_4bit_Structural_Modeling1(
input [3:0] a, b,
input Cin,
output [3:0] sum,
output carry );
wire [3:0] complement_b;
wire [2:0] carry_full_adder;
xor_gate xor0 (.a(b[0]), .b(Cin), .out(complement_b[0]));
xor_gate xor1 (.a(b[1]), .b(Cin), .out(complement_b[1]));
xor_gate xor2 (.a(b[2]), .b(Cin), .out(complement_b[2]));
xor_gate xor3 (.a(b[3]), .b(Cin), .out(complement_b[3]));
full_adder full_adder0 (.a(a[0]), .b(complement_b[0]), .Cin(Cin), .sum(sum[0]), .carry(carry_full_adder[0]));
full_adder full_adder1 (.a(a[1]), .b(complement_b[1]), .Cin(carry_full_adder[0]), .sum(sum[1]), .carry(carry_full_adder[1]));
full_adder full_adder2 (.a(a[2]), .b(complement_b[2]), .Cin(carry_full_adder[1]), .sum(sum[2]), .carry(carry_full_adder[2]));
full_adder full_adder3 (.a(a[3]), .b(complement_b[3]), .Cin(carry_full_adder[2]), .sum(sum[3]), .carry(carry));
endmodule
< Simulation >

4. 4bit - parallel add / subtractor ( Dataflow modeling )
< Source >
// 4bit Parallel adder / subtracter ( Dataflow modeling )
module Parallel_add_subs_4bit_Dataflow_Modeling0(
input [3:0] a, b,
input Cin,
output [3:0] sum,
output carry );
wire[4:0] result_value;
// Sign 값에 따라 덧셈 회로 연산을 할지? 뺄셈 회로 연산을 할지? 여부를 결정.
assign result_value = (Cin)? a - b : a + b;
// sum 포트에 덧셈 연산 출력
assign sum = result_value[3:0];
// Dataflow modeling에서 사용하는 +, - 연산은 32bit system 기준으로 연산한다.
// 따라서 4bit system. 기준에서 연산을 처리하는 Structural modeling과 약간의 차이점이 있다.
// 바로 감산 연산과정에서 발생하는 Carry 값이다 .
// 4bit 감산 연산에서 큰 값 - 작은 값 = carry 값이 1이다.
// 작은 값 - 큰값 = carry 값이 0 이다.
// Cin == 1 이면 뺄셈 연산을 수행 한다는 의미.
// 32bit system에서의 뺄셈 연산의 carry 값과 4bit system에서의 뺄셈 연산의 carry 값이 다르다.
// 4bit system에서 뺄셈 연산의 carry 값은 다음과 같다.
// 큰 값 - 작은 값 == 1, 작은 값 - 큰 값 == 0
// 32bit system에서 뺄셈 연산의 carry 값은 다음과 같다.
/// 큰값 - 작은 값 == 0, 작은 값 - 큰 값 == 1
assign carry = (Cin)? ~result_value[4] : result_value[4];
endmodule
< Simulation >
< Structural modeling 과 Dataflow modeling 의 차이점 >
1. 연산하는 bit system이 다르다.
Structural modeling은 4bit system에서 가감연산을 수행하지만, Dataflow modeling에서 사용하는 + (덧셈 회로), - (뺄셈 회로)은 32bit system에서 가감연산을 수행한다.
⭐ ⭐ ⭐ ⭐ ⭐
2. 뺄셈 연산에서 0bit ~ 5bit까지만 보았을 때, 서로 다른 Carry 값을 갖는다.
이를 설명하기 위해서는 아래 그림을 참고 할 필요가 있다.
아래 상황은 5 - 3 연산, 3 - 5 연산을 수행하는 경우이다.

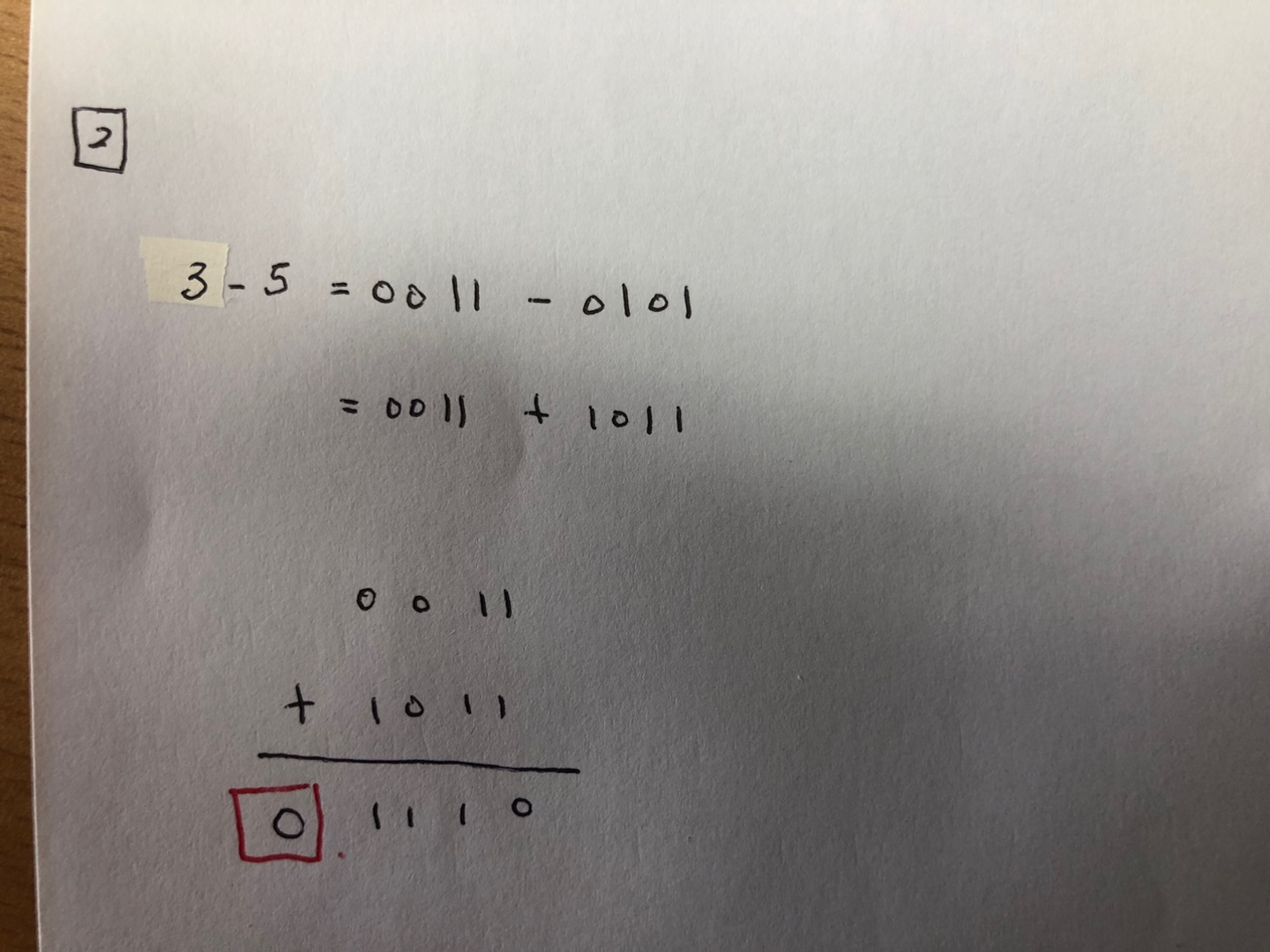
- 즉, 위 결과를 보면 알 수 있듯이 4bit 가감연산기에서 감산 연산을 수행한 경우,
- 큰 값 - 작은 값 을 하면 carry = 1
- 작은 값 - 큰 값 을 하면 carry = 0 - 하지만, 4bit system에서 32bit system으로 영역을 확장하면 다른 (?) 결과가 나타난다.


- 위 결과에서 알 수 있듯이 32bit도 MSB에서 발생한 carry는 4bit와 비슷하지만, 뒤 4bit만 보았을 때, 4번째 비트에서 발생한 carry 값이 4bit에서 발생한 carry 값과 반대라는 것을 확인할 수 있다.
- 즉, 32bit system에서 4bit 영역만 보았을 때 carry 는 다음과 같다.
- 큰 값 - 작은 값 을 하면 carry = 0
- 작은 값 - 큰 값 을 하면 carry = 1 - Q) 왜 32bit system에서 4bit system 처럼 carry를 맞출려고 하는가?
32bit system에 문제라도 있다는 거냐?
A) 아니다. 우리는 단지 Dataflow modeling에 사용되는 + (덧셈 회로), - (뺄셈 회로)는 32bit 기준으로 연산하기 때문에 4bit만 보려고 하는 우리의 의도(?)와 다르기 때문에 32bit system에서 33번째 비트에서 발생했던 carry를 5번째 비트에서 발생하도록 만들어 주는 것이다. 즉, 그냥 보기 위한 것이지. 32bit에는 아무런 문제 없다. - Q) 그럼 32bit system에서 33번째 발생한 carry를 5번째 비트로 어떻게 끌고 오는가?
A) 큰 값 - 작은 값, 작은 값 - 큰 값의 carry 결과가 정 반대임을 이용하여 다음과 같이 코드를 작성한다.
// Cin == 1 이면 뺄셈 연산을 수행 한다는 의미.
// 32bit system에서의 뺄셈 연산의 carry 값과 4bit system에서의 뺄셈 연산의 carry 값이 다르다.
// 4bit system에서 뺄셈 연산의 carry 값은 다음과 같다.
// 큰 값 - 작은 값 == 1, 작은 값 - 큰 값 == 0
// 32bit system에서 뺄셈 연산의 carry 값은 다음과 같다.
/// 큰값 - 작은 값 == 0, 작은 값 - 큰 값 == 1
assign carry = (Cin)? ~result_value[4] : result_value[4];- 가산 연산에 대해서는 관심 영역 외이며, 우리가 관심을 갖는 부분은 "감산 연산에서 큰 값 - 작은 값 or 작은 값 - 큰 값에서 발생한 carry 값을 32bit system도 33번째에서 갖는 것이 아닌 5번째 비트에서 해당 carry가 발생"하도록 만드는 것이다.
- 따라서 감산 연산일 때, 5번째 비트 값을 반전시켜줌으로서 의도대로 동작하도록 만들 수 있다.
5. 4bit 병렬 가감산기의 delay
- 이론적으로 보았을 때는 4bit 병렬 가감산기의 연산은 동시에 발생하는 것처럼 보이지만, 사실은 약간의 딜레이를 가지며, 0번째 Full adder부터 3번째 Full adder까지 차례 출력 값(sum, carry)를 출력시킨다.

- 즉, 다시 말해 1번째 FA (Full-adder)는 독립적으로 연산을 수행하지 못하고, 0번째 FA (Full-adder)로 부터 carry 값을 받아야지 연산을 시작할 수 있다.
- 따라서 0번째 FA (Full-adder)가 연산을 수행한 후, 그 다음으로 1번째 FA (Full-adder)가 연산을 수행한다.
- 동일한 이유로 1번째 FA(Full-adder)가 연산이 끝나야 2번째 FA (Full-adder)가 연산을 수행한다.
- 따라서 일반적인 병렬 가감산기는 딜레이 시간을 가지며, 이를 보완한 가감산기로 "초고속 가감산기", "초초고속 가감산기", "초초초고속 가감산기"가 존재한다.
- 하지만, Dataflow modeling 에서 +, - 연산자를 사용하면 자동적으로 초초초고속 가감산기로 연산하기 때문에 Dataflow modeling으로 설계한다면 이 부분에 대한 고려의 필요성이 줄어든다.
'RTL Design > Verilog RTL 설계' 카테고리의 다른 글
| Verilog RTL 설계 (6월 13일 - 5) (1) | 2024.06.15 |
|---|---|
| Verilog RTL 설계 (6월 13일 - 4) (1) | 2024.06.15 |
| Verilog RTL 설계 (6월 13일 - 2) (0) | 2024.06.14 |
| Verilog RTL 설계 (6월 13일 - 1) (0) | 2024.06.14 |
| Verilog RTL 설계 (6월 12일 - 3) (0) | 2024.06.13 |



